 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI for Character Animation: A Comprehensive Survey of Techniques, Applications, and Future Directions
Apr 27, 2025



Generative AI is reshaping art, gaming, and most notably animation. Recent breakthroughs in foundation and diffusion models have reduced the time and cost of producing animated content. Characters are central animation components, involving motion, emotions, gestures, and facial expressions. The pace and breadth of advances in recent months make it difficult to maintain a coherent view of the field, motivating the need for an integrative review. Unlike earlier overviews that treat avatars, gestures, or facial animation in isolation, this survey offers a single, comprehensive perspective on all the main generative AI applications for character animation. We begin by examining the state-of-the-art in facial animation, expression rendering, image synthesis, avatar creation, gesture modeling, motion synthesis, object generation, and texture synthesis. We highlight leading research, practical deployments, commonly used datasets, and emerging trends for each area. To support newcomers, we also provide a comprehensive background section that introduces foundational models and evaluation metrics, equipping readers with the knowledge needed to enter the field. We discuss open challenges and map future research directions, providing a roadmap to advance AI-driven character-animation technologies. This survey is intended as a resource for researchers and developers entering the field of generative AI animation or adjacent fields. Resources are available at: https://github.com/llm-lab-org/Generative-AI-for-Character-Animation-Survey.
UTNLP at SemEval-2022 Task 6: A Comparative Analysis of Sarcasm Detection using generative-based and mutation-based data augmentation
Apr 18, 2022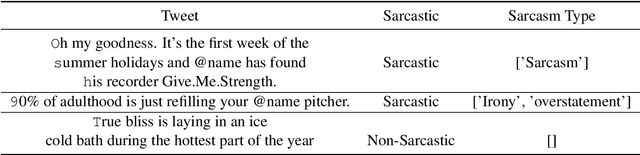
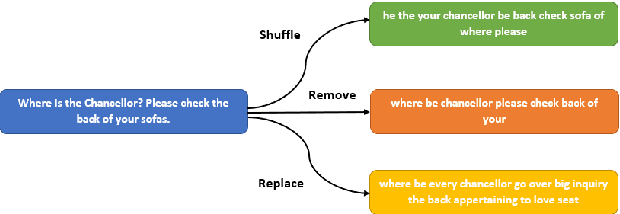
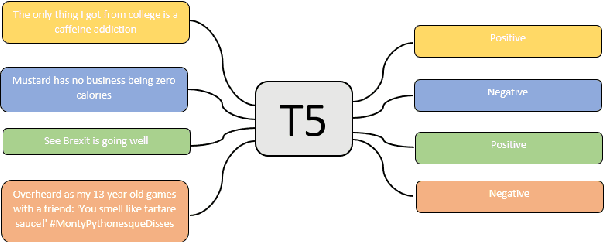
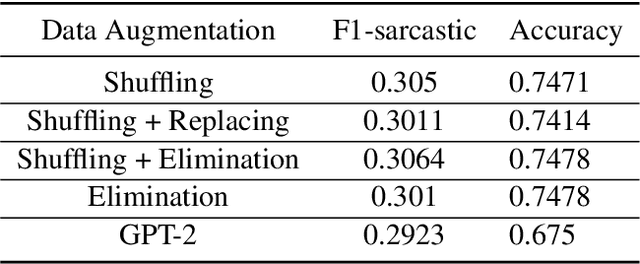
Sarcasm is a term that refers to the use of words to mock, irritate, or amuse someone. It is commonly used on social media. The metaphorical and creative nature of sarcasm presents a significant difficulty for sentiment analysis systems based on affective computing. The methodology and results of our team, UTNLP, in the SemEval-2022 shared task 6 on sarcasm detection are presented in this paper. We put different models, and data augmentation approaches to the test and report on which one works best. The tests begin with traditional machine learning models and progress to transformer-based and attention-based models. We employed data augmentation based on data mutation and data generation. Using RoBERTa and mutation-based data augmentation, our best approach achieved an F1-sarcastic of 0.38 in the competition's evaluation phase. After the competition, we fixed our model's flaws and achieved an F1-sarcastic of 0.414.